Performance Evaluation
To evaluate the runtime parameters of MPX, we have tested three benchmark suits: Phoenix 2.0, PARSEC 3.0 and SPEC CPU2006 (see methodology for details). To put the results into a context, we measured not only the two implementations of MPX, but also SAFECode, SoftBound and AddressSanitizer.
Note that some bars and numbers are missing on the plots. The missing results are due to errors at compile-/runtime or to unfixable bugs in programs; please refer to the usability page for more details. This especially concerns SAFECode and SoftBound: the prototype implementations we used were not stable enough to run on all benchmarks.
Note on native versions. Each of the tested approaches uses its own compiler, see details at methodology. The ratios shown in the plots are normalized against respective native versions, e.g., MPX (ICC) is normalized against the ICC native version, and SAFECode against Clang 3.2.0.
Note on AddressSanitizer. AddressSanitizer is supported on both GCC and Clang. We performed experiments with both versions and discovered that the Clang version performs better than GCC in most cases. Thus, the following plots show the Clang version of AddressSanitizer.
Main results
Note. All benchmarks were built using their single-threaded (sequential) versions in all experiments except Multithreading.
Performance
We start with the single most important parameter: runtime overhead of each approach.



lbm and namd under AddressSanitizer. These two SPEC benchmarks perform suspiciously fast under AddressSanitizer (better than native versions). We examined the assembly and made sure that this was not a bug in our experiments, but rather an artifact of AddressSanitizer compiler pass. In a nutshell, AddressSanitizer compiles lbm to a better-ordered sequence of SSE instructions and namd—to a better memory layout.
Observation 1: The ICC version of MPX performs significantly better than the GCC version in terms of performance. At the same time, ICC is less usable: only 30 programs out of total 38 (79%) build and run correctly, whereas 33 programs out of 38 (87%) work under GCC.
Observation 2: AddressSanitizer, despite being a software-only approach, performs on par with ICC-MPX and better than GCC-MPX. This unexpected result testifies that the HW-assisted performance improvements of MPX are offset by its complicated design. At the same time, AddressSanitizer provides worse security guarantees than MPX; see security page for details.
Observation 3: SAFECode and SoftBound show good results on Phoenix programs, but perform much worse—both in terms of performance and usability—on PARSEC and SPEC. First, consider SAFECode on Phoenix: due to the almost-pointerless design and simplicity of Phoenix programs, SAFECode achieves a low overhead of 5%. However, SAFECode could run only 18 programs out of 31 (58%) on PARSEC and SPEC and exhibited the highest overall overheads. SoftBound executed only 7 programs on PARSEC and SPEC (23%). Moreover, both SAFECode and SoftBound showed unstable behavior: some programs had overheads of more than 20X.
Instruction overhead
In most cases, performance overheads are dominated by a single factor: the increase in number of instructions executed in a protected application. It can be seen if we compare the performance overheads in the previous figure and the instruction overheads below; there is a strong correlation between the figures.



Observation 1: Instruction overhead does not directly correspond to the performance overhead. This is especially obvious on the example of AddressSanitizer: in some cases, the 2-3X increase in instructions leads to only 10-20% performance drop (consider pca, word_count, streamcluster, lbm, namd). Other factors that contribute to the performance overhead are IPC and cache behavior which we discuss next.
Observation 2: As expected, the optimized MPX (i.e., ICC version) has low instruction overhead due to its HW assistance (~70% lower than AddressSanitizer). Thus, one could expect sufficiently low performance overheads of MPX once the throughput and latencies of MPX instructions improve.
IPC
Many programs do not utilize the CPU execution-unit resources fully. For example, the theoretical IPC (instructions/cycle) of our machine is ~5, but many programs achieve only 1-2 IPC in native executions. Thus, memory-safety techniques benefit from underutilized CPU and partially mask their performance overhead.



Observation 1: MPX does not increase IPC. Our microbenchmarks indicate that this is caused by contention of MPX bounds-checking instructions on one execution port (P1). If this functionality would be available on more ports, MPX would be able to use instruction parallelism to a higher extent and the overheads would be lower.
Observation 2: Software-only approaches—especially AddressSanitizer and SoftBound—significantly increase IPC, partially hiding performance overheads.
Observation 3: Some programs have very low IPC (e.g, word_count, canneal, mcf, and omnet). This indicates that these programs are not compute-intensive but rather memory-intensive. The next figure proves it.
Cache utilization
Some programs are memory-intensive and stress the CPU cache system. If a native program has many L1 or LLC (last-level-cache) cache misses, then the memory subsystem becomes the bottleneck. In these cases, memory-safety techniques can partially hide their performance overhead.
Note. The sum of bars (the complete stack) for each program and each version represents the total number of memory accesses performed by the program. For example, native GCC execution of histogram performs 80% accesses in total, and its AddressSanitizer version—35% (normalized to the total number of executed instructions).



Observation 1: Most programs have good cache locality such that most memory accesses ended up in the L1 cache. Notable exceptions are word_count, canneal, and mcf which have many cache misses. Not surprisingly, these are the programs that also have very low IPC numbers.
Observation 2: The case of word_count under ICC-MPX is special. It has a huge instruction overhead of 4X, IPC close to native, and (as we will see next) many expensive bndldx and bndstx operations. And still its performance overhead is only 3X. Why? It appears the native version of word_count has a significant number of cache misses. They have high performance cost and therefore can partially mask the overhead of ICC-MPX.
MPX instructions
Instruction overhead is not the sole parameter that influences performance. In the case of MPX, the second most important factor is the type of instructions that are used in instrumentation. In particular, storing (bndstx) and loading (bndldx) bounds require two-level address translation—a very expensive operation that can break cache locality. To prove it, we measured the shares of MPX instructions in the total number of instructions of each program.
Note. Instruction overhead may also come from the management of Bounds Tables. Our microbenchmarks show that it can cause a slowdown of more than 100% in the worst case. However, this factor does not seem to have a noticeable impact in real-world applications. Even those applications that create hundreds of BTs (fluidanimate, canneal, dedup) exhibit a minor slowdown in comparison to other factors.
Note on methodology. An observant reader may notice that the plots contain numbers even for those programs marked as broken in other figures. This is because we disabled MPX error handling while gathering these statistics. The only exceptions are vips and x264 under ICC: our Intel Pin tool experienced an internal error on these programs.
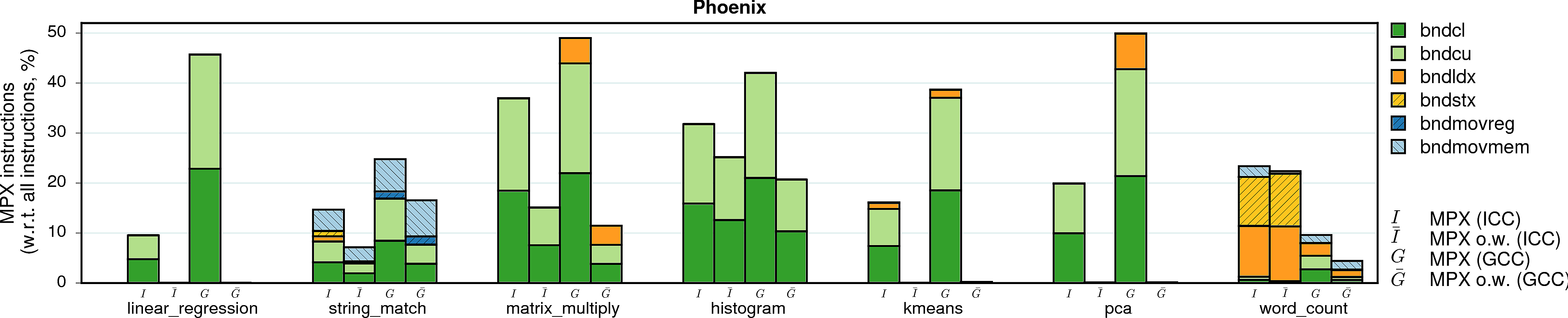
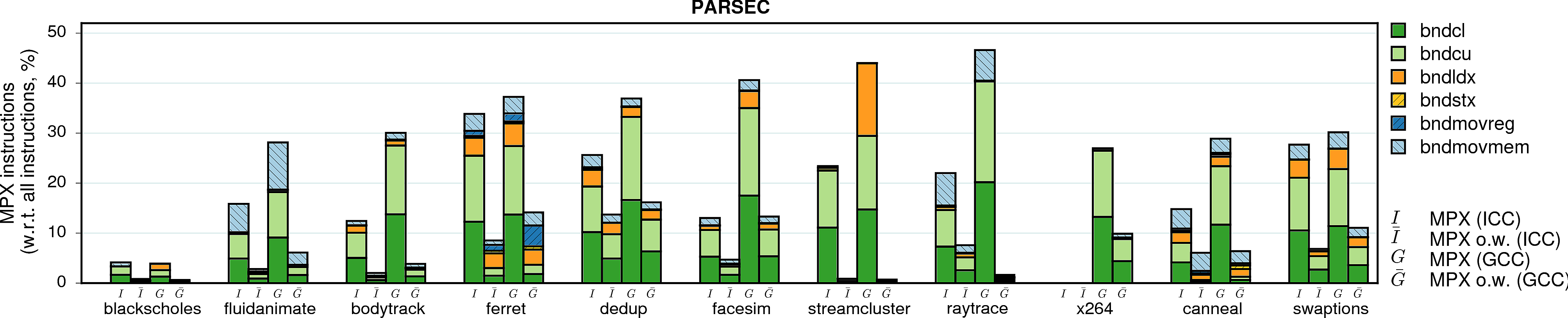
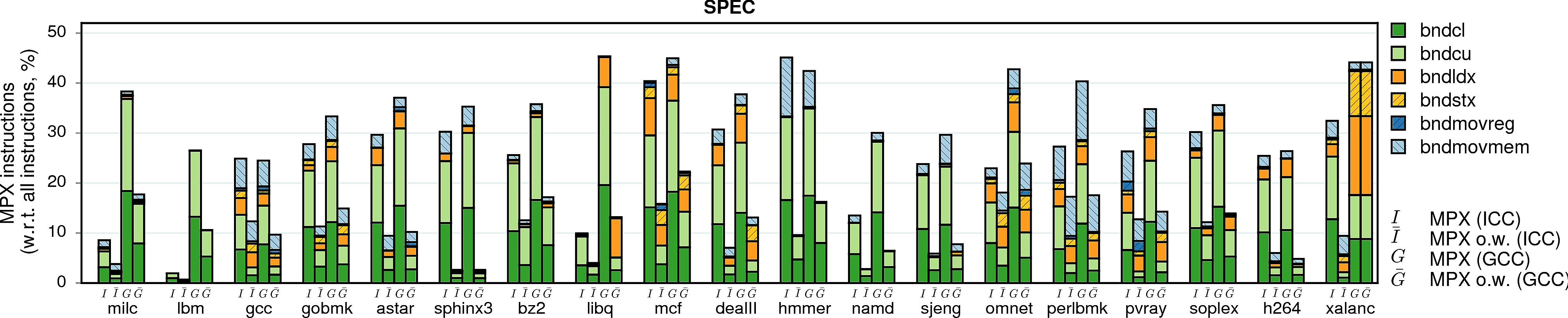
Observation 1: As expected, a lion share of all MPX instructions are bounds-checking bndcl and bndcu. Additionally, many programs need bndmov to move bounds from one register to another (bndmovreg) or spill bounds on stack (bndmovmem). Finally, pointer-intensive programs require the use of expensive bndstx and bndldx to store/load bounds in Bounds Tables.
Observation 2: The only-writes protection significantly reduces the number of inserted MPX instructions. In some cases, this number is almost-zero: linear_regression, swaptions, and sphinx3 are three examples. For these programs, only-writes protection results in almost-zero performance drop.
Observation 3: There is a strong correlation between the share of bndstx and bndldx instructions and performance overheads. For example, matrix_multiply under ICC-MPX almost exclusively contains bounds checks: accordingly, there is a direct mapping between instruction and performance overheads. However, the GCC-MPX version is less optimized and inserts many bndldxs, which leads to a significantly higher performance overhead. A similar explanation holds for streamcluster and xalanc.
Observation 4: The ICC-MPX version of word_count has a ridiculous share of bndldx/bndstx instructions. This is due to a performance bug in libchkp library of ICC that uses a naive algorithm for the memcpy wrapper. (More details can be found in our paper.)
Memory consumption
In some scenarios, memory overheads (more specifically, resident set size overheads) can be a limiting factor, e.g., for servers in data centers which co-locate programs and perform frequent migrations. Thus, memory overhead measurements are presented next.



Observation 1: On average, MPX has a 2.1X memory overhead under ICC version and 1.9X under GCC. It is a significant improvement over AddressSanitizer (2.8X). There are three main reasons for that. First, AddressSanitizer changes memory layout of allocated objects by adding “redzones” around each object. Second, it maintains a “shadow zone” that is directly mapped to main memory and grows linearly with the program’s working set size. Third, AddressSanitizer has a “quarantine” feature that restricts the reuse of freed memory. On the contrary, MPX allocates space only for pointer-bounds metadata and has an intermediary Bounds Directory that trades lower memory consumption for longer assess time.
Note. Quarantine zone is a temporal-protection feature of AddressSanitizer and, in principle, it gives an unfair advantage to Intel MPX which lacks this kind of protection. Indeed, if quarantine zone is disabled, AddressSanitizer’s memory overhead drops on average to ~1.5x for both PARSEC and SPEC, although the performance overhead is not influenced. We did not include this number into our main results because the goal of our study was to compare the solutions in their default configuration, without any tweaks from the side of end user.
Observation 2: SAFECode benefits from its pool-allocation technique. It exhibits very low memory overheads. Unfortunately, low memory consumption does not imply good performance.
MPX features
MPX has two main features that influence both performance and security guaranties: bounds narrowing and only-write protection.
When bounds narrowing is applied, each field of an object has its own bounds. It allows to detect overflows not only between objects, but also between fields inside a single object. This feature increases security level but may harm performance.
Only write protection, on the other side, improves performance by disabling checks on memory reads. Thus, it trades security guarantees for better performance.
Performance



Observation 1: Bounds narrowing has a negligible impact on performance because it does not change the number of checks. On the contrary, only-writes protection instruments less code and leads to lower slowdowns.
Memory consumption



Observation 1: Both bounds narrowing and only-writes protection seem to have no effect on memory consumption.
Multithreading
To evaluate the influence of multithreading, we measured and compared execution times of all benchmarks on 2 and 8 threads. The approach for enabling multithreading was different for different benchmark suites: for Phoenix it was enough to set a corresponding compilation flag; PARSEC required an alternative version of the source code (supplied with the suite). SPEC does not have a multithreaded version at all. Moreover, both SoftBound and SAFECode are not stable in multithreaded environments and therefore were excluded from measurements.
MPX and multithreading. MPX does not have any multithreading support. Though we experienced no multithreading issues in our benchmarks, we show how MPX can break in multithreaded environments.


Observation 1: As expected, the difference between native executions and our techniques is minimal. For MPX, it is caused by the absence of multithreading support, i.e., no additional code is executed in multithreaded versions. For AddressSanitizer, there is no need for explicit synchronization—the approach is thread-safe by design.
Observation 2: MPX experiences slowdowns on linear_regression (only GCC version) and word_count. Upon examining these cases, we found out that this anomaly is due to detrimental cache line sharing of BT entries.
Observation 3: matrix_multiply does not have a speedup in its native version. In a nutshell, there are 3.5X more LLC-loads on 8 threads than on 2. This happens due to hyperthreading—our machine has 4 physical cores with L1 and L2 caches shared among each two threads.
Observation 4: For raytrace, AddressSanitizer seems to exhibit only small speedup when going from 2 threads to 8. In reality, this is not a problem of AddressSanitizer but of the Clang compiler itself. The plot shows the native GCC version which—a rare corner case—scales much better than the native Clang version (2X speedup in comparison to 1.1X).
Observation 5: For swaptions, AddressSanitizer and MPXs scale significantly worse than native. It turns out that these techniques do not have enough spare IPC resources to fully utilize 8 threads in comparison to the native version (again, the problem of hyperthreading).
Observation 6: For streamcluster, MPX performs worse than AddressSanitizer and native versions. Similar to the previous observation, this is an issue with hyperthreading: MPX instructions saturate IPC resources on 8 threads and thus cannot scale as good as native.
Varying input sizes
In all previous experiments we used constant (reference) input sizes. However, different input sizes (working sets) may cause different cache behaviors, which in tern causes changes in overheads. To investigate the extent of such effects, we conducted a set of experiments with varying inputs. We picked four benchmarks from each suite and ran them with three inputs—small, medium, and large—each next one twice bigger than the previous. The results are presented in the next two sections.
Performance
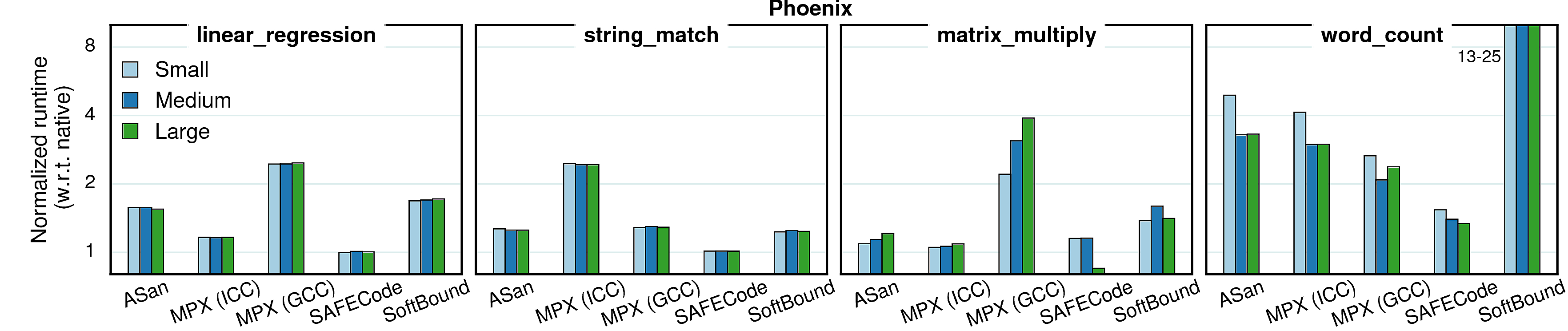
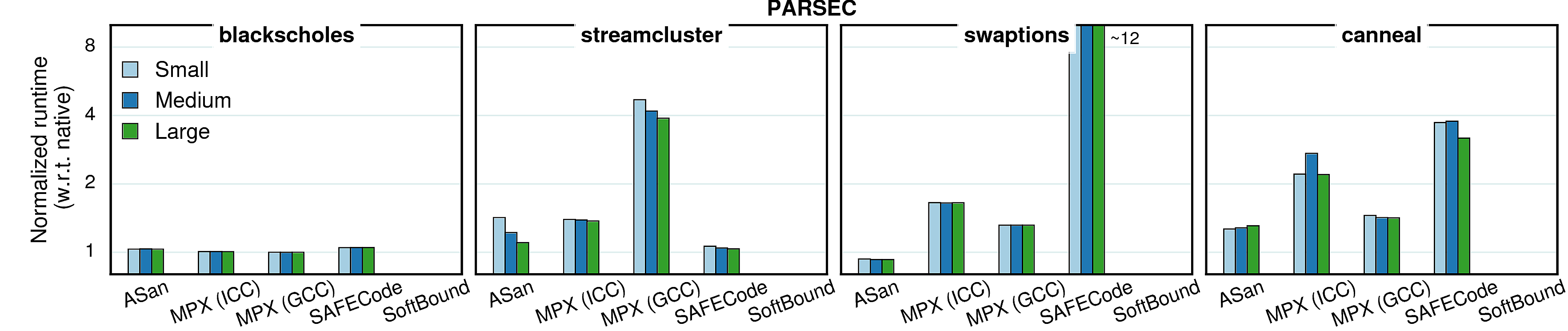
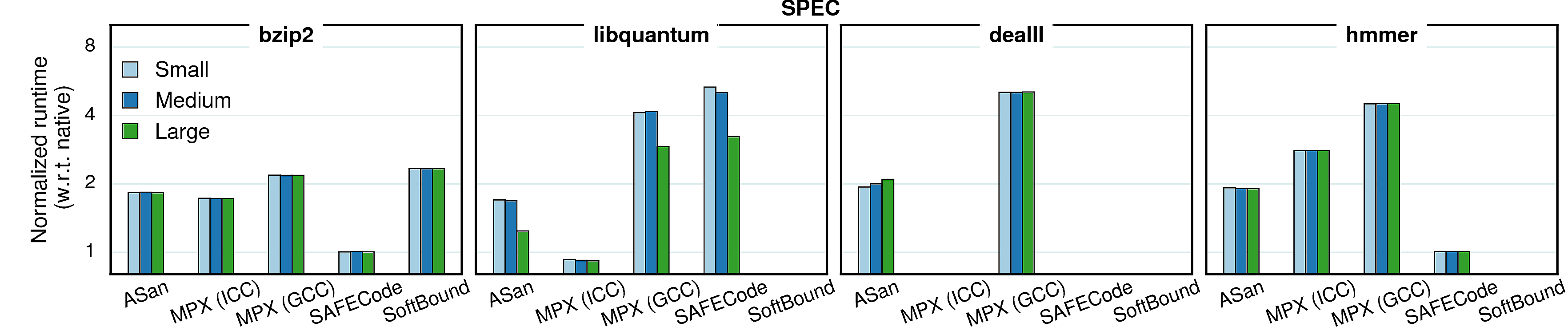
Generally, the input size has very little impact on performance overhead of any of the considered approaches, although there are some peculiar cases.
Observation 1: As mentioned in Cache utilization, the overhead in word_count is partially masked by the high number of cache misses. Since “small” input causes less cache misses, the masking effect is smaller and the overall overhead gets higher. The same goes for libquantum.
Observation 2: In the native version of matrix_multiply, IPC gets higher with the input growth, but in the GCC-MPX version it stays roughly the same. It means that GCC-MPX creates additional data dependencies that are partially blocking instruction-level parallelism (ILP). Correspondingly, the overhead grows.
Observation 3: The MPX-ICC version of canneal has higher overhead with medium input than with the two others, which is explained by cache locality. In the native version both small and medium inputs have very small percentage of LLC misses (0.08% and 3.67% correspondingly) and only the large input starts overflowing the cache (41.3% misses). The MPX-ICC version, on the contrary, has higher difference between small and medium inputs (39% and 68% LLC misses) than between medium and large (68% and 75%). Therefore, the performance overhead line has a bump on the medium input.
Memory consumption
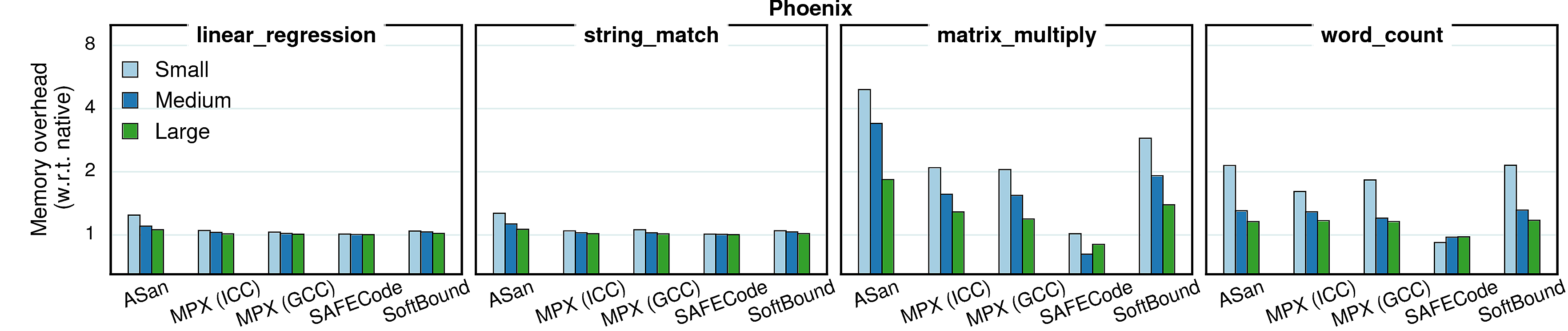
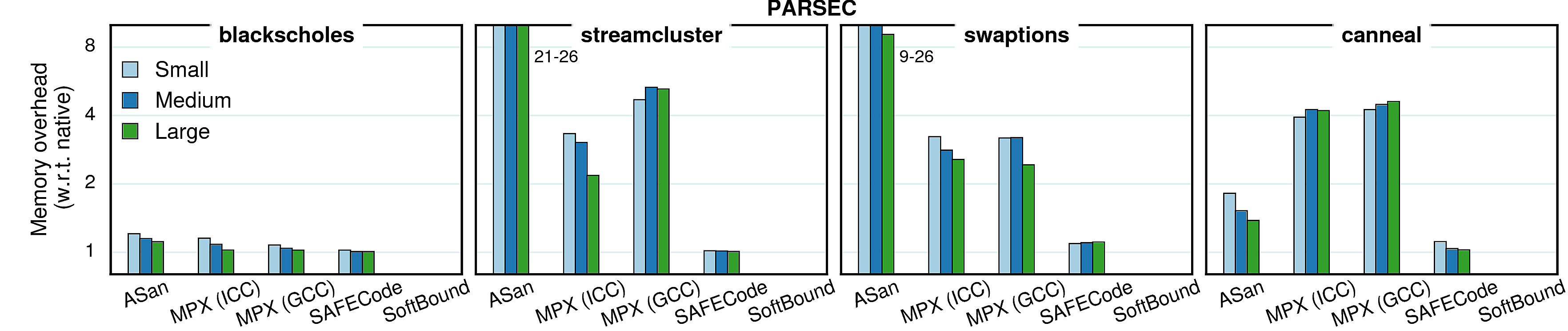
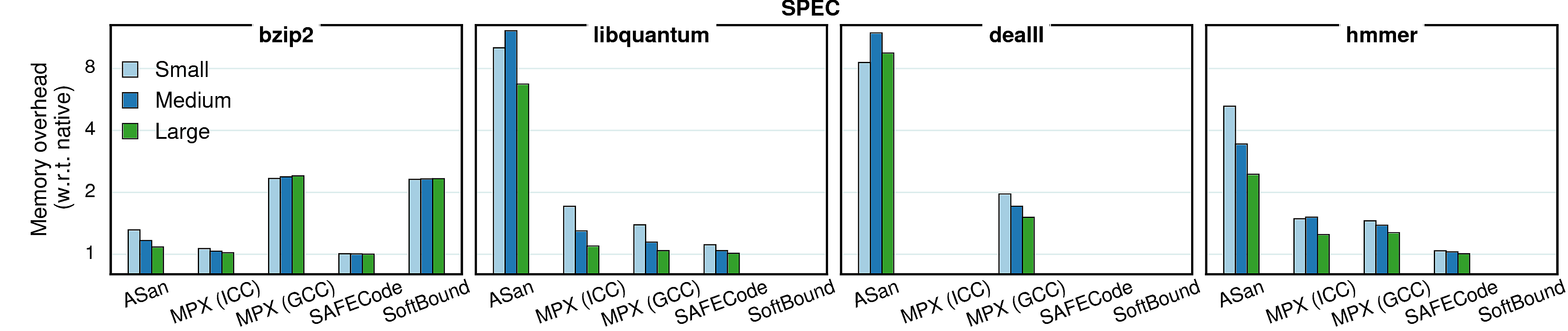
In contrast to performance which stays roughly the same with bigger inputs, the memory overheads tend to reduce when input size increases. It is caused by the fact that all protection approaches have a significant part of memory overhead which is constant (e.g., Shadow Memory in Address Sanitizer or Bounds Directory in MPX). Accordingly, when the memory consumption increases, the share of this constant overhead becomes smaller and the overall memory overhead decreases.
Observation 1: Some benchmarks have a reversed tendency in MPX versions—for both streamcluster and canneal the overhead increases with bigger inputs. It means that most of it comes from the dynamic part—Bounds Tables. Indeed, if we compare ICC and GCC versions of streamcluster, we see that ICC has a stable number of BTs (6 for all inputs) whereas in GCC the amount of BTs grows with bigger inputs (8, 11, and 16 BTs). Consequently, these two versions have opposite dynamics.
Observation 2: libquantum and dealII have a bump in AddressSanitizer versions. It is caused by the quarantine zone which may take a lot of space when memory regions are constantly allocated and freed. To prove it, we repeated the experiment with a quarantine zone of a small size (1MB): the dynamics became similar to other benchmarks, i.e., the overhead was steadily decreasing.
Performance on older CPU architectures
As we mention in the Hardware description, MPX-protected applications can be executed even on older Intel CPUs that do not support Intel MPX. In this case, MPX instructions will be executed as NOPs and consequently, no protection will be provided. Yet, NOPs are not free - each one takes 1 cycle to execute, they take space in caches, in the instruction pipeline, etc. It means that in such a scenario the application will be slowed down but will not get any additional security guaranties. To evaluate this effect, we run the same set of benchmarks on a Haswell machine. The results are presented in the following figures:



Other statistics
This data was removed from the main paper since it does not add more information to the existing discussion. Nevertheless, we leave it here for the sake of completeness.
Memory accesses in native executions
The overhead of memory-safety approaches usually comes from instrumentation of memory accesses and from wrappers on memory management functions: a bounds-check must be inserted before each indirect memory access. The below figure shows the percentage of memory accesses in native executions of programs under different compilers. The numbers prove: the higher the portion of memory accesses in the native version, the more checks are inserted and the higher the overall overhead becomes.
E.g., the correlation between the percentage of memory accesses, the number of instructions, and the runtime overhead is clearly seen for histogram and string_match on ICC.



Note on string_match. The 40%-memory-accesses spike on ICC—in comparison to 10% on GCC and Clang—accentuates the sometimes dramatic differences in compilers. Upon examining the assembly, we verified that this spike comes from the SSE2-heavy code; such code was generated only by ICC. (The 40% number is constituted mostly by the SSE2-stores to the bzeroed space.) This autovectorization optimization, despite increasing the number of memory accesses, provided a 30% better execution time than GCC.
Branches and TLB



Intel Pointer Checker
Before MPX, Intel had a software implementation of bounds checking in their compiler called Pointer Checker. The following figures compare performance of this feature with MPX - the improvement is unquestionable.


