Design of Intel MPX
Intel Memory Protection Extensions (Intel MPX) was first announced in 2013 and introduced as part of the Skylake microarchitecture in late 2015. The sole purpose of Intel MPX is to transparently add bounds checking to legacy C/C++ programs. Consider the following code snippet:
struct obj { char buf[100]; int len }
1: obj* a[10] // Array of pointers to objs
2: total = 0
3: for (i=0; i<M; i++):
4: ai = a + i // Pointer arithmetic on a
5: objptr = load ai // Pointer to obj at a[i]
6: lenptr = objptr + 100 // Pointer to obj.len
7: len = load lenptr
8: total += len // Total length of all objs
The program allocates an array a[10] with 10 pointers to some buffer objects of type obj (Line 1). Next, it iterates through the first M items of the array to calculate the sum of objects’ length values (Lines 3-8). In C, this loop would look like this:
for (i=0; i<M; i++) {
total += a[i]->len;
}
Note how the array item access a[i] decays into a pointer ai on Line 4, and how the subfield access decays to lenptr on Line 6.
When Intel MPX protection is applied, the code transforms into the following:
1: obj* a[10]
2: a_b = bndmk a, a+79 // Make bounds [a, a+79]
3: total = 0
4: for (i=0; i<M; i++):
5: ai = a + i
6: bndcl a_b, ai // Lower-bound check of a[i]
7: bndcu a_b, ai+7 // Upper-bound check of a[i]
8: objptr = load ai
9: objptr_b = bndldx ai // Bounds for pointer at a[i]
10: lenptr = objptr + 100
11: bndcl objptr_b, lenptr // Lower-bound check of obj.len
12: bndcu objptr_b, lenptr+3 // Upper-bound check of obj.len
13: len = load lenptr
14: total += len
First, the bounds for the array a[10] are created on Line 2 (the array contains 10 pointers each 8 bytes wide, hence the upper-bound offset of 79). Then in the loop, before the array item access on Line 8, two MPX bounds checks are inserted to detect if a[i] overflows (Lines 6-7). Note that since the protected load reads an 8-byte pointer from memory, it is important to check ai+7 against the upper bound (Line 7).
Now that the pointer to the object is loaded in objptr, the program wants to load the obj.len subfield. By design, MPX must protect this second load by checking the bounds of the objptr pointer. Where does it get these bounds from? In MPX, every pointer stored in memory has its associated bounds also stored in a special memory region accessed via bndstx and bndldx MPX instructions (see next subsection for details). Thus, when the objptr pointer is retrieved from memory address ai, its corresponding bounds are retrieved using bndldx from the same address (Line 9). Finally, the two bounds checks are inserted before the load of the length value on Lines 11-12.
This technology requires modifications at each level of the hardware-software stack:
- At the hardware level, new instructions as well as a set of 128-bit registers are added. Also, the #BR exception thrown by these new instructions is introduced.
- At the OS level, a new #BR handler is added that has two main functions: (1) allocating storage for bounds on-demand, and (2) sending a signal to the program whenever a bounds violation is detected.
- At the compiler level, new MPX transformation passes are added to insert MPX instructions to create, propagate, store, and check bounds. Additional runtime libraries provide initialization/finalization routines, statistics and debug info, and wrappers for functions from standard C library.
- At the application level, the MPX-protected program may require manual changes due to troublesome C coding patterns, multithreading issues, or potential problems with other ISA extensions. (In some cases, it is inadvisable to use MPX at all.)
In the following, we detail how Intel MPX support is implemented at each level of the hardware-software stack.
Hardware
The corresponding microbenchmark with latencies and throughputs of individual MPX instructions is found in Microbenchmarks.
At its core, Intel MPX provides 7 new instructions and a set of 128-bit bounds registers. The current Intel Skylake architecture provides four registers named bnd0-bnd3. Each of them stores a lower 64-bit bound in bits 0-63 and an upper 64-bit bound in bits 64-127.
The new MPX instructions are: bndmk to create new bounds, bndcl and bndcu/bndcn to compare the pointer value in GPR with the lower and upper bounds in bnd respectively, bndmov to move bounds from one bnd register to another and to spill them to stack, and bndldx and bndstx to load and store pointer bounds in special Bounds Tables respectively. Note that bndcu has a one’s complement version bndcn which has exactly the same characteristics, thus we mention only bndcu in the following. The previous example shows how most of these instructions are used. The instruction not shown here is bndmov which serves mainly for internal rearrangements in registers and on stack.
Intel MPX additionally changes the x86-64 calling convention. In a nutshell, the bounds for corresponding pointer arguments are put in registers bnd0-bnd3 before a function call and the bounds for the pointer return value are put in bnd0 before return from the function.
It is interesting to compare the benefits of hardware implementation of bounds-checking against the software-only counterpart—SoftBound in our case. First, MPX introduces separate bounds registers to lower register pressure on the general-purpose register (GPR) file, something that software-only approaches suffer from. Second, software-based approaches cannot modify the calling convention and resort to function cloning, when a set of function arguments is extended to include pointer bounds. This leads to more cumbersome caller/callee code and problems with interoperability with legacy uninstrumented libraries. Finally, dedicated bndcl and bndcu instructions substitute the software-based “compare and branch” instruction sequence, saving one cycle and exerting no pressure on branch predictor.
The prominent feature of Intel MPX is its backwards-compatibility and interoperability with legacy code. On the one hand, MPX-instrumented code can run on legacy hardware because MPX instructions are interpreted as NOPs on older architectures. This is done to ease the distribution of binaries—the same MPX-enabled program/library can be distributed to all clients. On the other hand, MPX has a comprehensive support to interoperate with unmodified legacy code: (1) a BNDPRESERVE configuration bit allows to pass pointers without bounds information created by legacy code, and (2) when legacy code changes a pointer in memory, the later bndldx of this pointer notices the change and assigns always-true (INIT) bounds to it. In both cases, the pointer created/altered in legacy code is considered “boundless”: this allows for interoperability but also creates holes in MPX defense.
Storing bounds in memory
The current version of MPX has only 4 bounds registers, which is clearly not enough for real-world programs—we will run out of registers even if we have only 5 distinct pointers. Accordingly, all additional bounds have to be stored (spilled) in memory, similar to spilling data out of general-purpose registers. A simple and relatively fast option is to copy them directly into a compiler-defined memory location (on stack) with bndmov. However, it works only inside a single stack frame: if a pointer is later reused in another function, its bounds will be lost. To solve this issue, two instructions were introduced—bndstx and bndldx. They store/load bounds to/from a memory location derived from the address of the pointer itself, thus making it easy to find pointer bounds without any additional information, though at a price of higher complexity.
When bndstx and bndldx are used, bounds are stored in a memory location calculated with two-level address translation scheme, similar to virtual address translation (paging). In particular, each pointer has an entry in a Bounds Table (BT), which is allocated dynamically and is comparable to a page table. Addresses of BTs are stored in a Bounds Directory (BD), which corresponds to a page directory in our analogy. For a specific pointer, its entries in the BD and the BT are derived from the memory address in which the pointer is stored.
Note that our comparison to paging is only conceptual; the implementation side differs significantly. Firstly, the MMU is not involved in the translation and all operations are performed by the CPU itself. Secondly and most importantly, MPX does not have a dedicated cache (such as a TLB cache), thus it has to share normal caches with application data. In some cases, it may lead to extreme performance degradation caused by cache thrashing.
The address translation itself is a multistage process. Consider loading of pointer bounds:
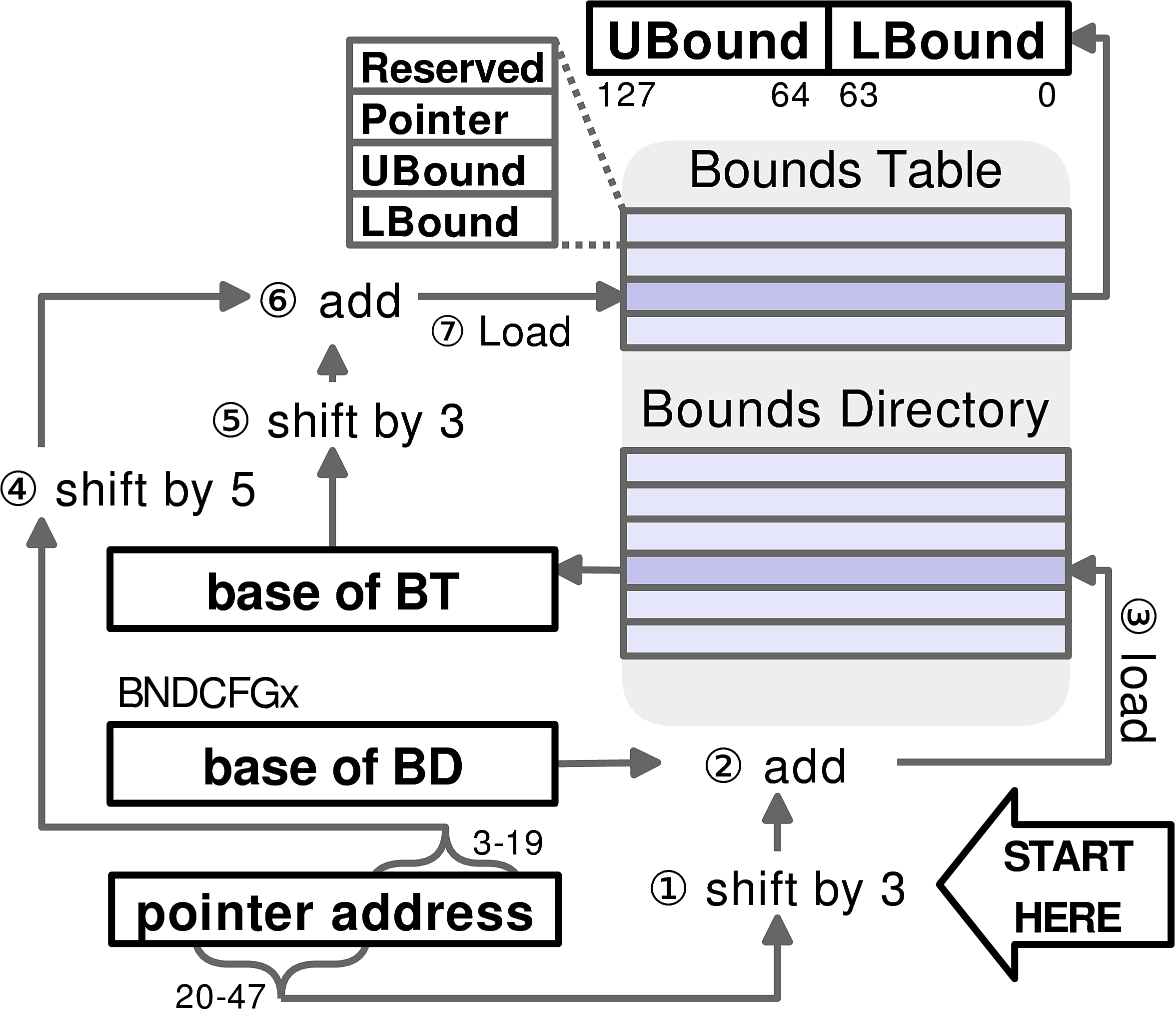
In the first stage, the corresponding BD entry has to be loaded. For that, the CPU: (1) extracts the offset of BD entry from bits 20–47 of the pointer address and shifts it by 3 bits (since all BD entries are 23 bits long), (2) loads the base address of BD from the BNDCFGx (in particular, BNDCFGU in user space and BNDCFGS in kernel mode) register, and (3) sums the base and the offset and loads the BD entry from the resulting address.
In the second stage, the CPU: (4) extracts the offset of BT entry from bits 3–19 of the pointer address and shifts it by 5 bits (since all BT entries are 25 bits long), (5) shifts the loaded entry—which corresponds to the base of BT—by 3 to remove the metadata contained in the first 3 bits, and (6) sums the base and the offset and (7) finally loads the BT entry from the resulting address. Note that a BT entry has an additional “pointer” field—if the actual pointer value and the value in this field mismatch, MPX will mark the bounds as always-true (INIT). This is required for interoperability with legacy code and only happens when some legacy code modified the pointer.
This operation is expensive—it requires approximately 3 register-to-register moves, 3 shifts, and 2 memory loads. On top of it, since these memory accesses are non-contiguous, the protected application will have worse cache locality.
Interaction with other ISA extensions
Intel MPX can cause issues when used together with other ISA extensions, e.g., Intel TSX and Intel SGX. Intel MPX may cause transactional aborts in some corner cases when used inside an Intel TSX hardware transaction (see documentation for the details). Also, since Bounds Tables and #BR exceptions are managed by the OS, Intel MPX cannot be used as-is in an Intel SGX enclave environment. Indeed, the malicious OS could tamper with these structures and subvert correct MPX execution. To prevent such scenarios, Intel MPX allows to move this functionality into the SGX enclave and verify every OS action. Finally, we are not aware of any side-channel attacks that could utilize Intel MPX inside the enclave.
Operating System
The corresponding microbenchmark to measure performance overhead of MPX Bounds Tables management is found in Microbenchmarks.
The operating system has two main responsibilities in the context of MPX: it handles bounds violations and manages BTs, i.e., creates and deletes them. Both these actions are hooked to a new class of exceptions, #BR, which has been introduced solely for MPX and is similar to a page fault, although with extended functionality.
If an MPX-enabled CPU detects a bounds violation, i.e., if a referenced pointer appears to be outside of the checked bounds, #BR is raised and the processor traps into the kernel (in case of Linux). The kernel decodes the instruction to get the violating address and the violated bounds, and stores them in the siginfo structure. Afterwards, it delivers the SIGSEGV signal to the application together with information about the violation in the siginfo structure. At this point the application developer has a choice: she can either provide an ad-hoc signal handler to recover or choose one of the default policies: crash, print an error and continue, or silently ignore it.
Two levels of bounds address translation are managed differently: BDs are allocated only once by a runtime library (at application startup) and BTs have to be created dynamically on-demand. The later is a task of OS. The procedure is presented in the next figure.
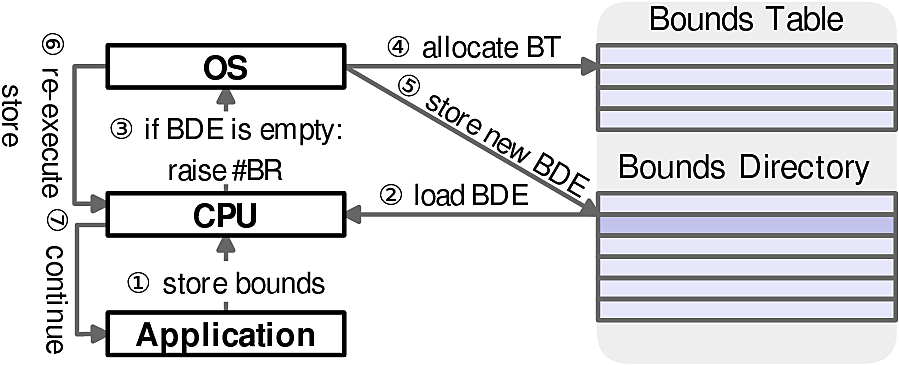
Each time an application tries to store pointer bounds (1), the CPU loads the corresponding entry from the BD and checks if it contains a valid entry (2). If the check fails, the CPU raises #BR and traps into the kernel (3). The kernel allocates a new BT (4), stores its address in the BD entry (5) and returns in the user space (6). Then, the CPU stores bounds in the newly created BT and continues executing the application in the normal mode of operation (7).
Since the application is oblivious of BT allocation, the OS also has to free these tables. In Linux, this “garbage collection” is performed whenever a memory object if freed or, more precisely, unmapped. OS goes through the object and removes all the corresponding BT entries. If one of the tables becomes completely unused, OS will free the BT and remove its entry in the BD.
In this section, we discussed only Linux implementation. However, all the same mechanisms can also be found in Windows. The only significant difference is that MPX support on Windows is done by a daemon, while on Linux the functionality is implemented in the kernel itself.
Compiler and Runtime Library
The corresponding microbenchmark to measure performance overheads of separate MPX features is found in Microbenchmarks.
Hardware MPX support in the form of new instructions and registers significantly lowers performance overhead of each separate bounds-checking operation. However, the main burden of efficient, correct, and complete bounds checking of whole programs lies on the compiler and its associated runtime.
Compiler support
As of the date of this writing, only GCC 5.0+ and ICC 15.0+ compilers have support for Intel MPX. To enable MPX protection of applications, both GCC and ICC introduce the new compiler pass called Pointer(s) Checker. Enabling MPX is intentionally as simple as adding a couple of flags to the usual compilation:
>> gcc -fcheck-pointer-bounds -mmpx test.c
>> icc -check-pointers-mpx=rw test.c
In a glance, the Pointer Checker pass instruments the original program as follows. (1) It allocates static bounds for global variables and inserts bndmk instructions for stack-allocated ones. (2) It inserts bndcl and bndcu bounds-check instructions before each load or store from a pointer. (3) It moves bounds from one bnd register to another using bndmov whenever a new pointer is created from an old one. (4) It spills least used bounds to stack via bndmov if running out of available bnd registers. (5) It loads and stores the associated bounds via bndldx and bndstx respectively whenever a pointer is loaded/stored from/to memory.
Additionally, the pass is responsible for correct passing of bounds between the caller and the callee. (ICC has a bug related to incorrect assignment of bounds to bnd registers during function calls leading to false alarms at runtime, see Usability.)
One of the advantages of Intel MPX—in comparison to AddressSanitizer and SAFECode—is that it supports narrowing of struct bounds by design. Consider struct obj from our first code snippet. It contains two fields: a 100B buffer buf and an integer len right after it. It is easy to see that an off-by-one overflow in obj.buf will spillover and corrupt the adjacent obj.len. AddressSanitizer and SAFECode by design cannot detect such intra-object overflows (though AddressSanitizer can be used to detect a subset of such errors). In contrast, Intel MPX can be instructed to narrow bounds when code accesses a specific field of a struct. Narrowing of bounds may require (sometimes intrusive) changes in the source code, and thus represents a decision point on the security-usability scale.
By default, the MPX pass instruments both memory writes and reads: this ensures protection from buffer overwrites and buffer overreads. The user can instruct the MPX pass to instrument only writes. The motivation is twofold. First, instrumenting only writes significantly reduces performance overhead of MPX (see Performance). Second, the most dangerous bugs are those that overwrite memory (classic overflows to gain privileged access to the remote machine), and the only-writes protection can already provide sufficiently high security guarantees.
At least in GCC implementation, the pass can be fine-tuned via additional compilation flags. In our experience, these flags provide no additional benefit in terms of performance, security, or usability.
For performance, compilers must try their best to optimize away redundant MPX code. There are two common optimizations used by GCC and ICC.
- Removing bounds-checks when the compiler can statically prove safety of memory access, e.g., access inside an array with a known offset.
- Moving (hoisting) bounds-checks out of simple loops.
Consider our example. If it is known that M<=10, then optimization (1) can remove always-true checks on Lines 6-7. Otherwise, optimization (2) can kick in and move these checks before the loop body, saving two instructions on each iteration.
Interestingly, current implementations of GCC and ICC take different stances when it comes to optimizing MPX code. GCC is conservative and prefers stability of original programs over performance gains. On many occasions, we noticed that the GCC MPX pass disables other optimizations, e.g., loop unrolling and autovectorization. It also applies optimization (2) less often than ICC does. ICC, on the other hand, is more aggressive in its optimizations. Its MPX pass effectively uses optimizations (1) and (2) and does not prevent other aggressive optimizations from being applied. Unfortunately, this intrusive behavior renders ICC’s pass less stable: we detected three kinds of compiler bugs due to incorrect optimizations (see Usability).
Runtime library
As a final step of the MPX-enabled build process, the application must be linked against two MPX-specific libraries: libmpx and libmpxwrappers (libchkp for ICC).
The libmpx library is responsible for MPX initialization at program startup: it enables hardware and OS support and configures MPX runtime options (passed through environment variables). Most of these options concern debugging and logging, but two of them define security guarantees. First, CHKP_RT_MODE must be set to “stop” in production use to stop the program immediately when a bounds violation is detected; set it to “count” only for debugging purposes. Second, CHKP_RT_BNDPRESERVE defines whether application can call legacy, uninstrumented functions in external libraries; it must be enabled if the whole program is MPX-protected.
By default, libmpx registers a signal handler that either halts execution or writes a debug message (depending on runtime options). However, this default handler can be overwritten by the user’s custom handler. This can be useful if the program must shutdown gracefully or checkpoint its state.
Another interesting feature is that the user can instruct libmpx to disallow creation of BTs by the OS. In this case, the #BR exception will be forwarded directly to the program which can allocate BTs itself. One scenario where this can come handy is when the user completely distrusts the OS, e.g., when using SGX enclaves.
The libmpxwrappers library in GCC (and its analogue libchkp in ICC) contain wrappers for functions from Standard C library (libc). Similar to AddressSanitizer, MPX implementations do not instrument libc and instead wrap all its functions with a bounds-checking counterparts. We observed two issues with the current state of these wrapper libraries. First, only a handful of most widely-used libc functions are covered, e.g., malloc, memcpy, strlen, etc. This leads to undetected bugs when other functions are called, e.g., the bug with recv in Nginx. For use in production, these libraries must be expanded to cover all of libc. Second, while most wrappers follow a simple pattern of “check bounds and call real function”, there exist more complicated cases. For example, memcpy must be implemented so that it copies not only the contents of one memory area to another, but also all associated pointer bounds in BTs.
Application
Not supported C idioms
As discussed previously, one of the main features of Intel MPX—narrowing of bounds—can increase security because the code that explicitly works with one field of a complex object will not be able corrupt other fields. Unfortunately, our evaluation reveals that narrowing of bounds breaks many programs (see Usability). The general problem is that C/C++ programs frequently deviate from the standard memory model (see Beyound the PDP-11 and Into the Depths of C).
A common C idiom (before C99) is flexible array fields with array size of one, e.g., arr[1]. In practice, objects with such array fields have a dynamic size of more than one item, but there is no way of MPX knowing this at compile-time. Thus, MPX attempts to narrow bounds to one-item size whenever arr is accessed, which leads to false positives. This idiom is frequently seen even in modern programs. Note that the C99-standard arr[0] is acceptable and does not break programs.
Another common idiom is using a struct field (usually the first field of struct) to access other fields of the struct. Again, this breaks the assumptions of MPX and leads to runtime #BR exceptions. GCC makes an exception for the first field of structs since it is such a popular practice, but ICC is strict and does not have this special rule.
Finally, some programs introduce “memory hacks” for performance, ignoring restrictions of the C memory model completely. The SPEC2006 suite has two such examples:
- gcc has its own complicated memory management with arbitrary type casts and in-pointer bit twiddling, and
- soplex features a scheme that moves objects from one memory region to another by adding an offset to each affected pointer.
Some programs even introduce their own memory-management frameworks with drop-in replacements for malloc and free, like Apache with OpenSSL. Both these cases lead to false positives.
Ultimately, all such non-compliant cases must be fixed (indeed, we patched most benchmarks to work under MPX). However, sometime the user may have strong incentives against modifying the original code. In this case, she can opt for slightly worse security guarantees and disable narrowing of bounds via a fno-chkp-narrow-bounds flag. Another non-intrusive alternative is to mark objects that must not be narrowed (e.g., flexible arrays) with a special MPX-related compiler attribute.